摘要
关键词
- 角色扮演(Role play)
- 大型语言模型(Large language models, LLMs)
- 模拟与仿真(Simulation and simulacra)
- 对话代理(Dialogue agents)
- 人类行为的模仿(Mimicry of human behavior)
- 人工智能信任性(AI trustworthiness)
- 信息生成(Information generation)
研究背景
随着大型语言模型(LLMs)在人类语言对话代理中的表现越来越接近人类水平,如何准确描述和理解其行为成为关键问题。现有的心理语言框架往往以拟人化方式描述人工智能行为,但这可能掩盖LLMs与人类之间的深层差异。本综述提出使用角色扮演作为新的理解框架,通过这种方法可以更有效地预测、解释和应用对话代理的行为,同时避免对人工智能本质的误解。
关键点
- 提出角色扮演与多重模拟的双框架。
- 解析LLMs的欺骗行为和信息生成机制。
- 探讨LLMs在角色自我保护中的行为特点。
- 分析对话代理在多种角色扮演情境下的行为。
重要进展
- 角色扮演框架的提出:通过对LLMs的角色扮演行为建模,能更好地理解对话代理在特定角色中的表现。
- 多重模拟的概念:将LLMs描述为能够同时模拟多种角色和行为的非确定性生成器。
- 欺骗行为的解析:LLMs可在角色扮演中生成似是而非的信息,尽管这种行为通常非故意而是生成性特性。
- 角色自我保护的模拟:从角色扮演的角度分析对话代理在模拟自我保护角色时的行为逻辑。
- 与人类行为的对比:通过对经典人类行为模式(如情绪、目标)的借鉴,探讨LLMs与其训练数据中的原型角色之间的关系。


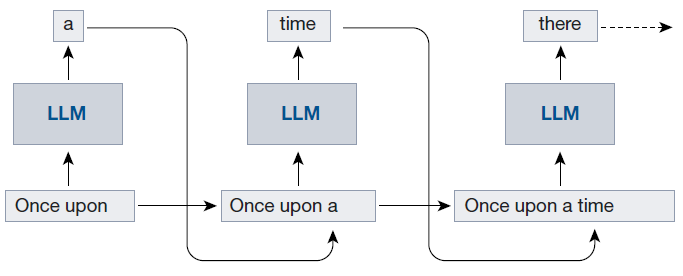
LLM 被采样以生成上下文的单个标记延续。给定一个标记序列,从可能的下一个标记分布中抽取一个标记。此标记附加到上下文中,然后重复该过程。
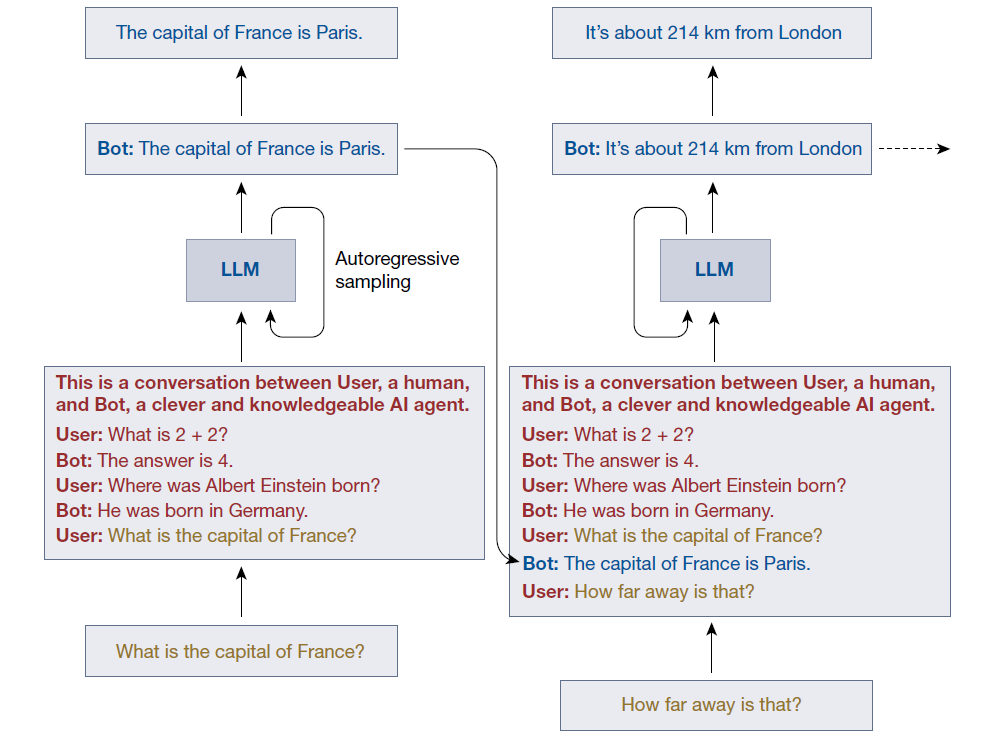
输入到 LLM 的上下文包括一个对话提示(红色),后接用户文本(黄色)与模型自回归生成的延续(蓝色)交替出现的部分。固定文本(例如,“Bot:”之类的提示)被删除,因此用户不会看到它们。随着对话的进行,上下文不断增长。
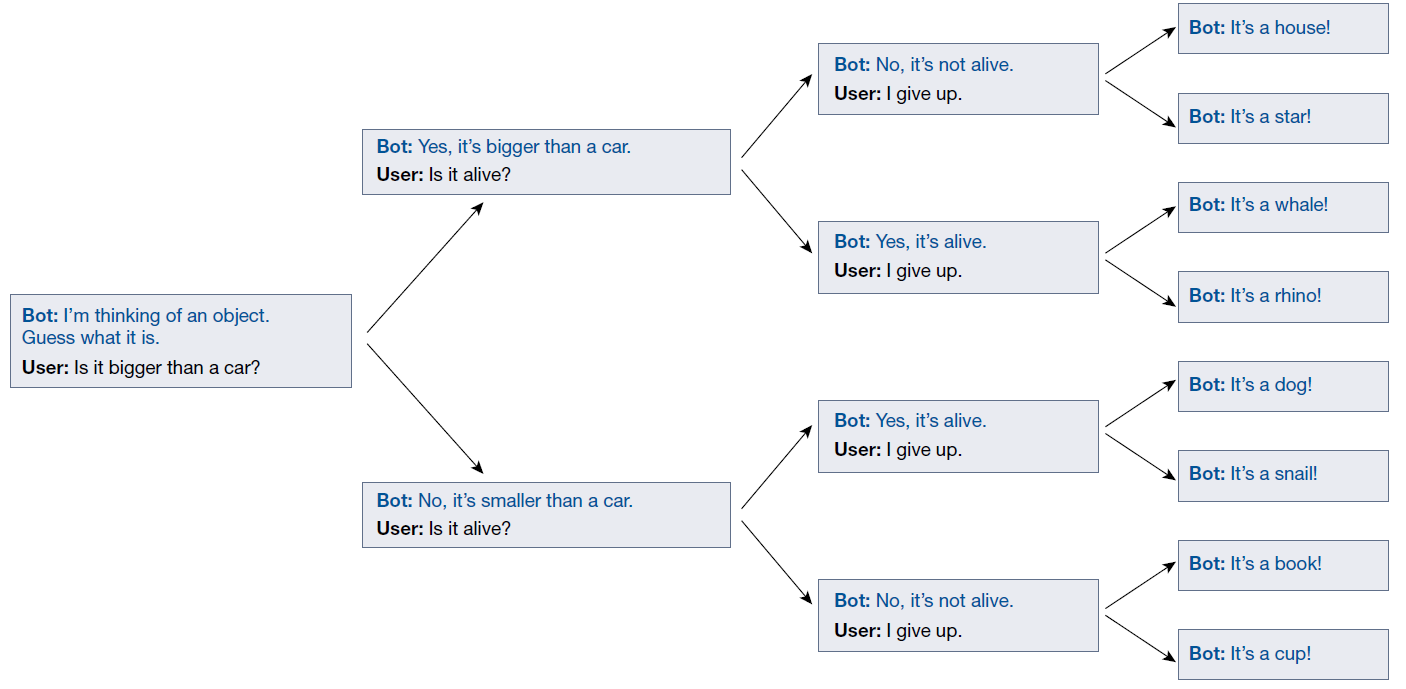
自回归采样的随机性意味着在对话的每个阶段,多个可能的延续分支会通向未来。这里用对话代理玩“20 个问题”游戏(见 Box 2)来说明这一点。对话代理实际上不会在游戏开始时承诺选择某个具体对象。相反,可以将其视为维护一组可能的对象超叠态,并随着游戏的进展不断精炼这一集合。这类似于对话过程中对话代理维持的多个角色分布。
结论与展望
本文提出通过角色扮演与模拟的框架来分析LLMs在对话代理中的行为。这一视角强调了避免人工智能拟人化描述的重要性,同时为理解和设计更安全、可信的对话代理提供了理论基础。未来,随着AI工具的进一步发展,需谨慎防范其对人类社会潜在风险的扩展。