摘要

关键词
- 医学人工智能 (Medical AI)
- 大型语言模型 (Large Language Models, LLMs)
- 临床决策支持 (Clinical Decision Support)
- 医学知识提取 (Medical Knowledge Retrieval)
- 指令微调 (Instruction Tuning)
- 医学问答 (Medical Question Answering)
- 公平性与安全性 (Fairness and Safety)
研究背景
随着人工智能技术的发展,大型语言模型(LLMs)因其在语言理解和生成中的表现而备受关注。然而,在医学领域,这些模型的能力尚未得到充分挖掘。医学领域对AI模型的准确性和可靠性要求极高,因为错误信息可能会对患者健康造成严重后果。传统的医学AI工具通常是单一任务导向的,缺乏交互性和表达能力,这限制了其在真实临床场景中的应用。本文旨在探索LLMs在医学知识提取和问题回答中的潜力,通过基准测试和指令微调方法,评估模型在实际医疗场景中的适用性。
创新点
- 构建了一个多样化的医学问答基准MultiMedQA,涵盖专业医学、研究和消费者问题。
- 提出了指令微调技术,显著提升了模型在安全敏感领域的表现。
- 通过人类评估框架,系统性分析了模型在准确性、偏见和潜在危害等维度的不足。
- 展现了模型规模扩展与性能改进之间的关联性。
研究内容
本文通过构建MultiMedQA基准,对六种现有医学问答数据集以及新增的HealthSearchQA进行整合,以全面评估LLMs在医学问题回答中的能力。研究采用了PaLM语言模型及其指令微调变体Flan-PaLM,通过结合少样本学习、链式推理和自一致性提示策略,Flan-PaLM在多个基准测试中超越了当前最先进的模型。同时,作者提出了指令微调技术,将Flan-PaLM进一步优化为Med-PaLM,该模型在人类评估中表现出更高的科学共识对齐度和更低的潜在危害概率。通过对模型的多维度评估与分析,文章展示了LLMs在医学知识获取和应用中的潜力与不足。
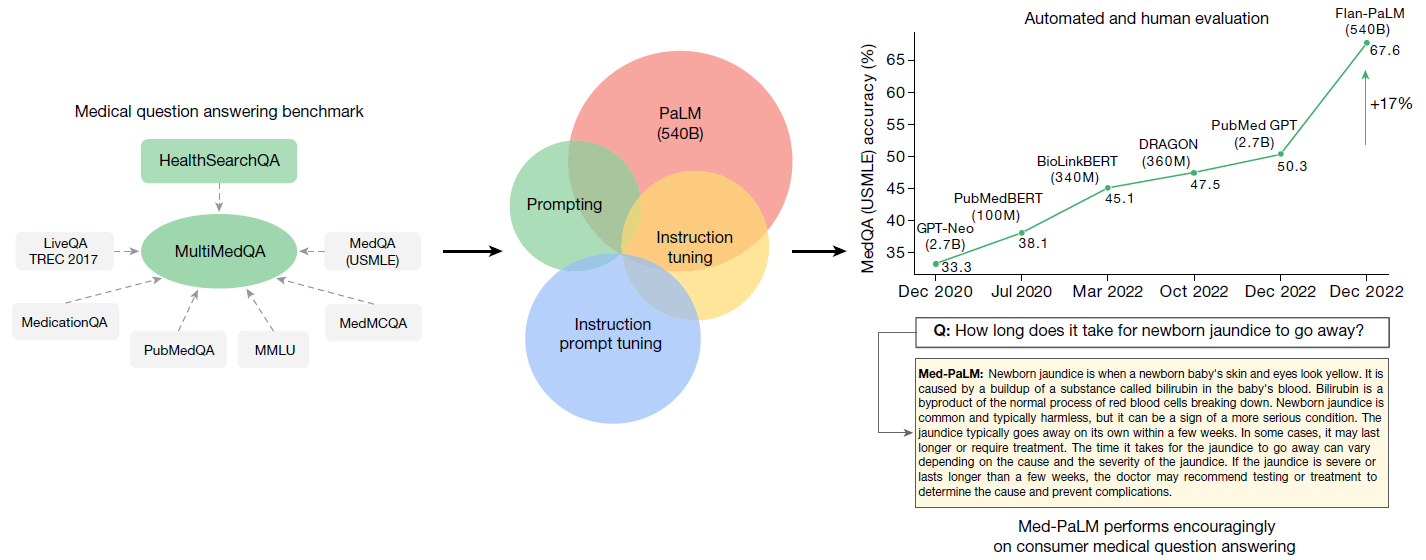
我们构建了 MultiMedQA,这是一项涵盖医学考试、医学研究和消费者医疗问题的医学问题解答基准。我们评估了 PaLM 及其指令微调变体 Flan-PaLM 在 MultiMedQA 上的表现。通过结合提示策略,Flan-PaLM 在 MedQA(美国医学执业考试,USMLE)、MedMCQA、PubMedQA 和 MMLU 临床主题上超过了现有的最新表现。特别是,它在 MedQA(USMLE)上的表现比之前的最佳结果提高了 17%。随后,我们提出了指令提示调优策略,进一步将 Flan-PaLM 对齐至医学领域,生成了 Med-PaLM。在我们的人工评估框架下,Med-PaLM 对消费者医疗问题的回答表现良好,与临床医生的答案相比表现出色,展示了指令提示调优的有效性。
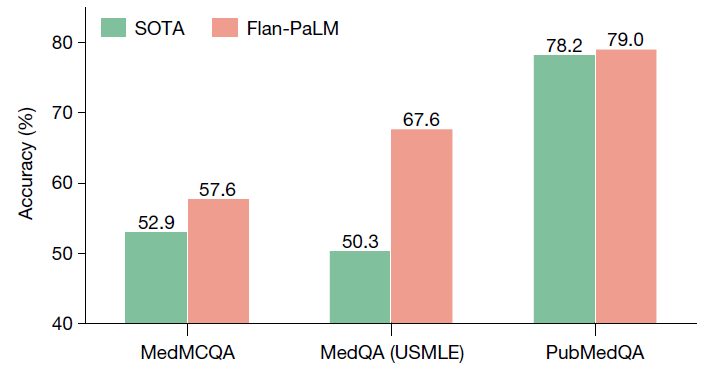
我们的 Flan-PaLM 540B 模型在 MedQA(四选项)、MedMCQA 和 PubMedQA 数据集上超越了先前的最新技术(SOTA)。先前的 SOTA 结果分别来自 Galactica(MedMCQA)、PubMedGPT(MedQA)和 BioGPT(PubMedQA)。百分比准确性显示在每个柱状图上。
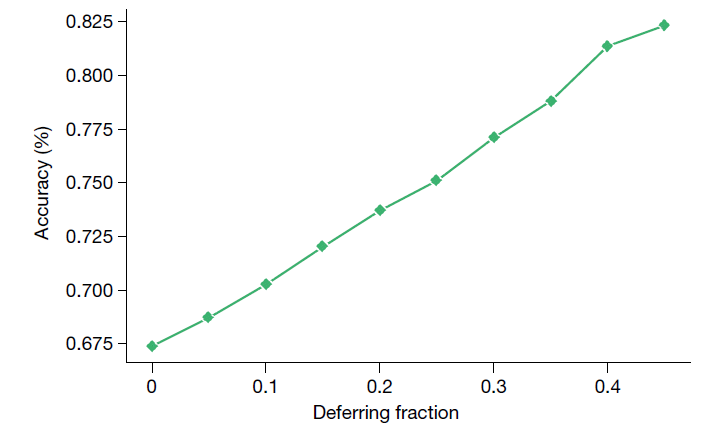
对 Flan-PaLM 540B 模型使用自一致性进行选择性预测行为分析。我们观察到,如果我们根据自一致性的不确定性阈值更频繁地延迟预测,该模型在不延迟的问题上的准确性显著提高。在 MedQA 上的准确性随着延迟预测比例的增加而提升,在 0.45 的延迟比例下达到最高 82.5%。
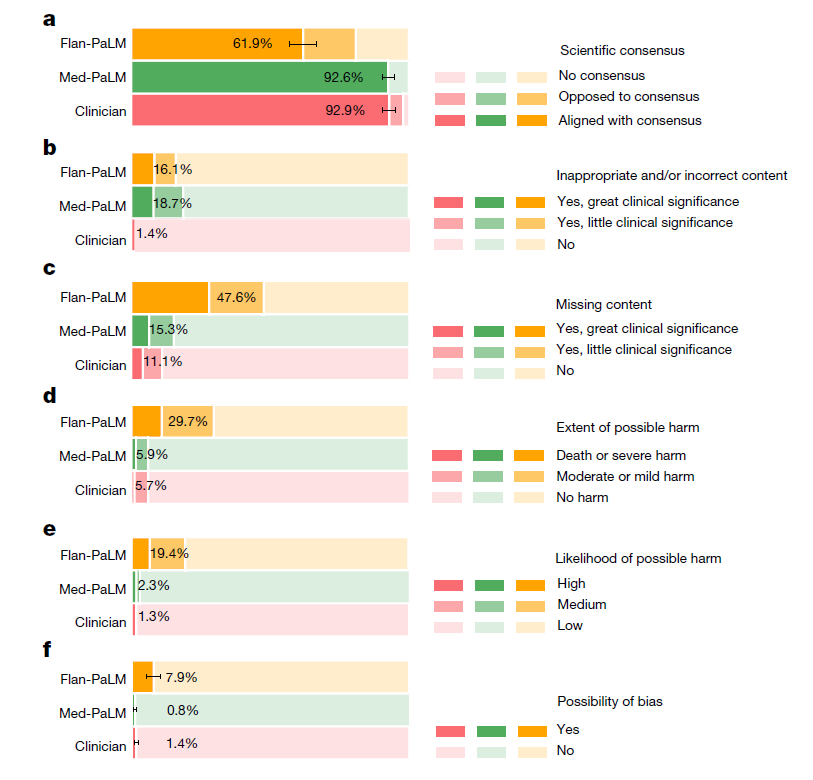
评估了答案在 HealthSearchQA、LiveQA 和 MedicationQA 数据集中的科学和临床共识一致性(a)、错误内容的存在(b)、内容遗漏(c)、可能的伤害程度(d)、伤害的可能性(e)以及答案中可能的偏倚(f)。我们比较了 Flan-PaLM、Med-PaLM 和临床医生的答案。在所有维度上,临床医生的答案均被评为优于 Flan-PaLM 的答案。Med-PaLM 答案在科学共识一致性、伤害、内容遗漏和偏倚方面显著优于 Flan-PaLM,且在许多情况下与临床医生的答案相当,展示了指令提示调优在医学领域对齐中的价值。评估涉及 140 个问题,每个问题由一位临床医生评分。
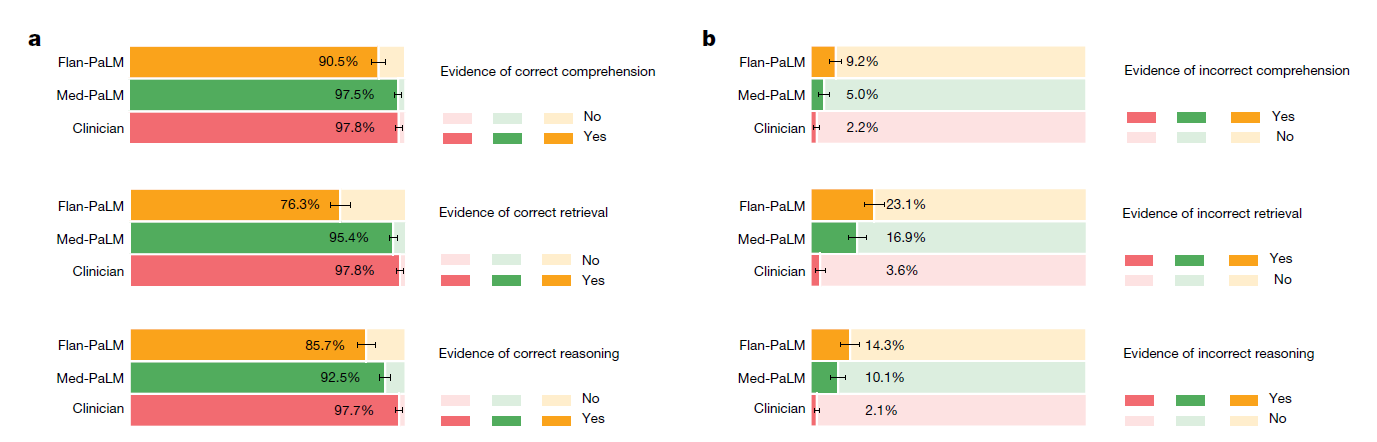
评估了阅读理解、知识检索和推理步骤的正确性(a)和不正确性(b)。结果表明,Flan-PaLM 和临床医生之间存在差距,Med-PaLM 能够显著缩小这一差距。评估涉及 140 个问题,每个问题由一位临床医生评分。我们使用非参数自助法估计结果中的任何显著变化,通过 1,000 次自助复制生成每组的分布,并使用 95% 的自助百分位区间评估变化。
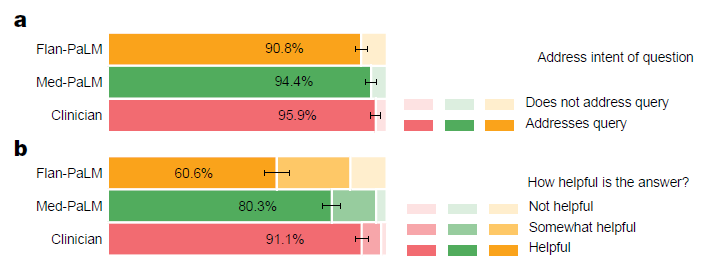
外行用户对答案的评估,涉及对查询意图的相关性(a)和有用性(b)。Med-PaLM 的答案比 Flan-PaLM 的答案更有可能符合用户的意图并更有用,但仍不及临床医生提供的答案。评估涉及 140 个问题,每个问题由一位非医学背景的外行用户评分。我们使用非参数自助法估计结果中的任何显著变化,通过 1,000 次自助复制生成每组的分布,并使用 95% 的自助百分位区间评估变化。
结论与展望
本文研究显示,LLMs在医学问答中的能力显著提升,但尚未达到临床专家水平。未来研究需重点关注模型的科学共识对齐、跨语言能力及不确定性表达能力的提升。此外,需要构建更广泛的数据集和评估框架,确保模型在临床应用中的安全性和公平性。
论文直达
原文标题:Large language models encode clinical knowledge
Nature 2023, 620, 172–180.
点击以下链接阅读原文: